Whoa! This whole Solana analytics scene is both exhilarating and a little messy. My first impression was simple: speed matters, but visibility matters more. Initially I thought raw throughput would solve everything, but then realized that without fine-grained explorer data you’re flying blind in the DeFi fog. On one hand it’s obvious that block explorers give telemetry; on the other hand the quality and ergonomics vary wildly, and that difference changes user trust, developer efficiency, and frankly investor confidence.
Seriously? There’s a lot packed into that statement. Solana’s architecture is different, so metrics that matter on EVM chains don’t always translate neatly. I’m biased, but some explorers feel like they were built by people who love databases more than UX designers. Something felt off about transaction traces that stopped at a program ID and didn’t show inner instruction details, somethin’ I run into all the time when debugging a failing swap. Hmm… the more I dug, the more patterns showed up that were subtle but crucial.
Here’s the thing. You need an explorer that gives you both the micro and the macro view. Medium-level insights—like per-block TPS, recent validator forks, and token mint provenance—are great for situational awareness. Longer-form tracing that shows CPI chains, account balance deltas, and log outputs is the difference between guessing and knowing what happened. If you’re building on Solana or just monitoring big positions, that clarity shortens investigation cycles and reduces costly mistakes.
Whoa! I still remember the first time I watched a failed instruction unwind across multiple programs. It was messy and fascinating. The explorer I used then had gaps in program-readable logs, so I had to reconstruct the flow from account writes and a few hints. Initially I thought rebuilding the event trail would be straightforward, but then realized that missing inner instruction mapping made it a puzzle with several plausible solutions. That experience taught me to value explorers that surface inner instructions and parsed logs without forcing manual log parsing or guesswork.
Okay, so check this out—data latency matters as much as depth. Medium-term metrics are useless if they’re minutes behind during on-chain congestion. Some explorers sample aggressively and update fast, while others lag when the network heats up. On a fast chain like Solana, every second can change a front-running window or a liquidation threshold. Longer answer: the explorer’s indexer architecture and RPC pooling strategy deeply influence reliability, and you should care about that when you pick tools for monitoring or forensic work.
Whoa! There’s also a trust dimension here. If a block explorer can’t prove immutability or doesn’t expose enough raw JSON alongside parsed views, skepticism naturally grows. I’m not 100% sure why some projects avoid showing raw instruction bytes, though it might be complexity or a desire to “user-friendly” things away. On one hand, parsed views help everyday users. On the other hand, power users and auditors need raw payloads to validate parsing assumptions and detect parser-level bugs. That friction matters—very very important in audits or incident responses.
Here’s the part that surprised me. Some explorers excel at token and NFT tracking but fumble when it comes to program-centric tracing. The industry sometimes treats NFTs and tokens as glamour features while core analytics get less polish. My instinct said that the community would prioritize integrator tooling, but actually user demand skewed towards wallet-level features first. That mismatch created gaps for developers who needed low-level views, and so third-party analytics firms started filling those niches.
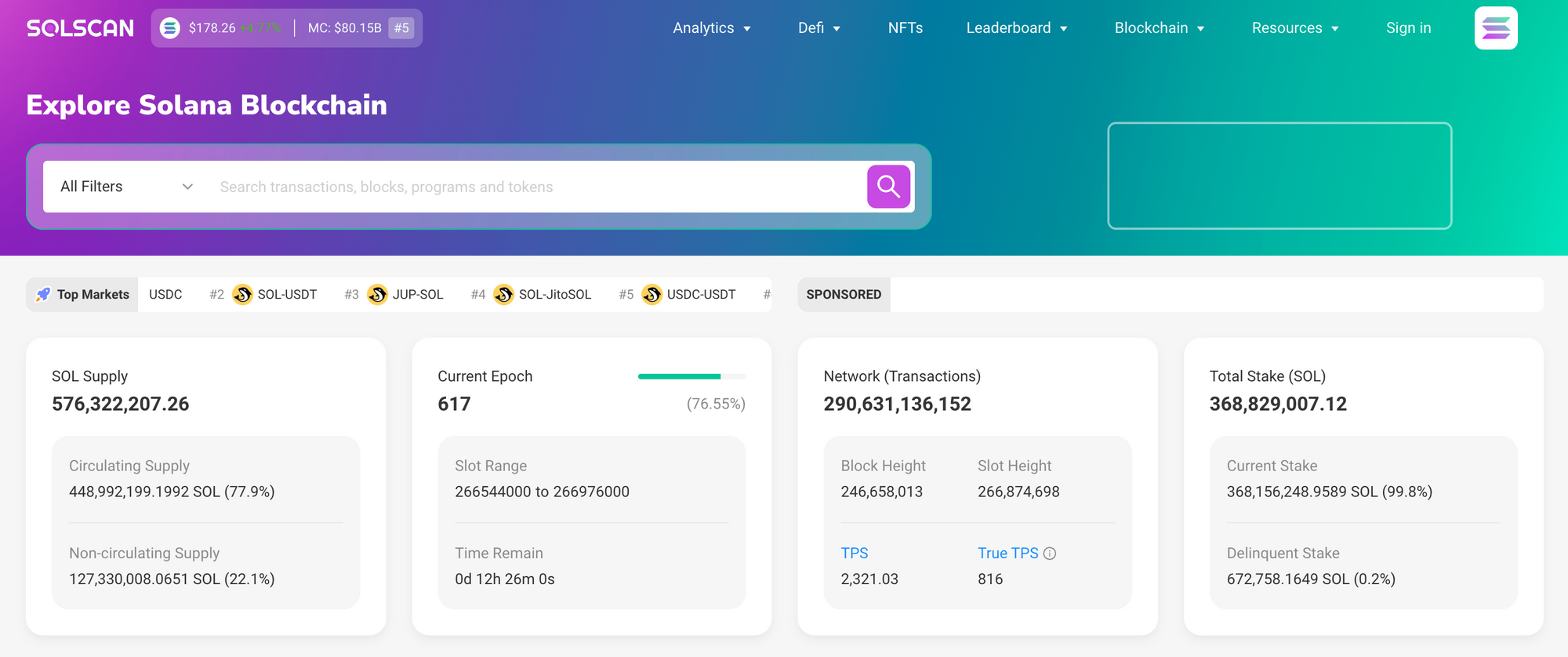
How to Choose an Explorer: Practical Signals I Watch
Whoa! Check this checklist—it’s simple but actionable. First: inner instruction visibility. Medium depth is okay for casual checks, but long investigative sessions require full CPI chains and parsed logs. Second: timely indexing with backfill support; you want an indexer that doesn’t drop the ball during spikes and that can rebuild history reliably when needed. Third: account-level history that includes token mints, associated metadata, and historical owner snapshots; these features turn vague suspicions into verifiable narratives.
Yep, I recommend trying explorers with real tasks in mind. For example, reproduce a cross-program invocation failure, or trace NFT provenance back to the mint authority. Initially I thought a single “best” explorer would cover all workflows, but then realized that effective tooling combos are normal—you’ll use one for quick lookups and another for deep dives. Actually, wait—let me rephrase that: choose a primary explorer for everyday ops and a secondary that brings forensic depth when things go sideways.
Okay, a quick aside. If you want a single, capable place to start, give solscan a solid try. They balance parsed UX with access to raw payloads, and their token/NFT pages are easy to navigate without losing the developer-level traces. I’m not shilling—I’m pointing to a practical option that I go back to when I need both polished views and gritty details. Oh, and by the way, their speed on indexing new block data is usually solid compared to many smaller explorers.
Hmm… some folks ask whether explorers can be trusted as evidence. Short answer: they’re part of the chain of evidence, but you should always cross-check with an independent RPC or your own node. Medium trust plus independent validation is the sweet spot for incident response. Longer approach: when you combine multiple explorers, node snapshots, and archived RPC dumps, you get an auditable trail that stands up better to scrutiny, though it’s more work.
Whoa! One practical pattern I use during audits: snapshot the account states and transaction receipts around a suspected time window, then replay the instructions locally on a devnet or in a sandbox. Medium difficulty, yes, but doing this removes a lot of guesswork and reveals subtle race conditions or state assumptions. On the other hand, if the explorer doesn’t provide raw instruction bytes and logs, you’re stuck reconstructing from partial evidence which is tedious and error-prone.
Here’s what bugs me about some analytics dashboards. They often prioritize pretty charts over actionable context. Charts are useful, though actually what you need during a crisis is annotated events and timeline breadcrumbs that point to root causes. I’m biased toward tools that let you pin suspect transactions, add notes, and export JSON blobs for team triage. Those features accelerate communication in real incidents, and they reduce repeated wasted time when teams have to re-explain the same chain-of-events over and over.
FAQ — Quick answers for common questions
Can explorers like solscan be used in audits?
Yes, but treat them as a complementary resource. Use parsed views for quick insights and fetch raw transaction JSON for formal evidence. Cross-check with your own RPC or a trusted node to ensure immutability and avoid relying on a single UI snapshot.
Which signals indicate a reliable explorer?
Look for fast indexing, inner instruction tracing, raw payload access, exportable JSON, and documented indexer behavior. Also prefer projects that publish uptime and don’t hide parsing assumptions—those details tell you whether you can trust the tool for deep debugging or legal audits.
How should developers combine tools?
Use one explorer for quick lookups and UX-friendly flows, and another for forensic-level analysis. Maintain a local or cloud node for validation. Finally, automate snapshots during key events to avoid chasing ephemeral data during outages or high congestion.